


Scientific journal
Bulletin of the Altai Academy of Economics and Law
Print ISSN 1818-4057
Online ISSN 2226-3977
List of the Higher Attestation Commission
APPLICATION OF DIGITAL TOOLS IN RISK MANAGEMENT

Введение
В последние годы инструментарий специалистов по оценке рисков значительно расширился, что объясняется возникновением целых классов инновационных технологий. Тенденции развития рискологии – области исследования рисков – сопряжены с усложнением технологий, ориентированных на сбор и анализ больших массивов данных. Так, в купе со комплексными вычислениями, носящими характер подбора более удачных значений коэффициентов перед экзогенными переменными, классические сценарные методы, например, различные варианты имитационных моделирований, метод Монте-Карло и другие, получили дальнейший виток развития. В этой связи актуальным и своевременным является рассмотрение возможностей применения технологий искусственного интеллекта и «bigdata» к такой области управления, как риск-менеджмент [1].
Материалы и методы исследования
Исследование потенциала цифровых технологий для оценки рисков осуществлено путем использования общенаучных методов познания:
– анализ отечественных научных публикаций, прогнозно-аналитических работ, материалов научных конференций, семинаров и круглых столов, статистических данных, периодических изданий, материалов зарубежных и отечественных исследователей, а также информации, доступной в сети Интернет;
– системный анализ опыта внедрения цифровых технологий в структуру риск-менеджмента российских и зарубежных компаний.
Результаты исследования и их обсуждение
Методологию исследования составили сравнительный, аналитический и системный методы. Особый интерес представляют альтернативы симплекс-методам, которые могут быть полезными при решении задачи на оптимизацию при помощи применения программы Excel для получения более детального представления о возможностях и ограничениях использования цифровых технологий при решении распространённых задач на оптимизацию. В качестве базового условия можно взять ситуацию, при которой перед риск-менеджером стоит задача оптимизации производства шоколадных батончиков (А, В, С). Так, для создания такого изделия используются три ингредиента – какао, сахар и начинка. Следует сделать допущения, что оценщику, исходя из исторических данных и договоренностей с заинтересованными сторонами, известна прибыль за реализацию партии. Вместе с тем предприятие обладает конкретным объемом запасов необходимых для производства ресурсов.
В этой связи необходимо определить оптимальный план производства изделий под условие максимизации прибыли, акцентируя внимание на управлении риском недополучения прибыли при выборе невыгодного варианта с учетом существующих ограничений – ценовых факторов и величины запасов. Решение задачи сводится к поиску корней в модели, которую рассмотрим далее. В свою очередь условные исходные данные представлены в таблице 1.
Таблица 1
Производственная карта
|
Сырье |
Стоимость производства |
Запас сырья |
||
|
А |
B |
С |
||
|
Какао |
18 |
15 |
10 |
360 |
|
Сахар |
6 |
4 |
8 |
190 |
|
Начинка |
4 |
3 |
6 |
160 |
|
Прибыль |
10 |
11 |
12 |
|
Источник: составлено автором.
Для решения данной можно воспользоваться надстройкой Excel «Поиск решений». Для этого следует предварительно осуществить ряд вычислений, а именно создать целевую функцию прибыли путем использования описанных переменных, отвечающих за объемы каждого вида компонентов продукта (А, В, С – х1, х2, х3 соответственно). Таким образом, целевая функция прибыли будет иметь вид x1*10+x2*11+x3*12, где множители у переменных х – наша прибыль за реализацию условной единицы продукции.
В условие задачи заложены реальные ограничения в виде запасов сырья: чтобы программа их учла, аналогично целевой функции прибыли напишем соответствующие функции для каждого компонента конфет, а для удобства работы программы примем все переменные за единицы (на данном этапе можем выбрать любое число, так как программа, осуществляя вычисления, будет их изменять с целью максимизации функции прибыли). Определив необходимые значения для «поиска решений», запускаем алгоритм и получаем результаты, содержащиеся в таблице 2.
Таблица 2
Результаты работы функции
|
Кол-во партий (переменные х) |
0 |
12,25 |
17,625 |
|
Функции сырья (ограничения) |
360 |
<= |
360 |
|
190 |
<= |
190 |
|
|
142,5 |
<= |
160 |
|
|
Итог прибыли |
346,25 |
||
Источник: составлено автором.
Результаты работы алгоритма показывают, что производить тип товара А нецелесообразно – в зависимости от условий договоров поставки мы можем произвести 12 неполных партий товара типа В или 17 партий товара типа В, соответственно. Как следствие, работа столь простого инструмента, как функция в базовой программе Excel позволила минимизировать риск недополучения прибыли, отказавшись от производства товара А, поскольку наполнитель расходуется в большей степени, нежели остальные ресурсы, что дополнительно подсвечивает необходимость закупки начинки в меньших объемах.
Таблица 3
Итог подбора параметров
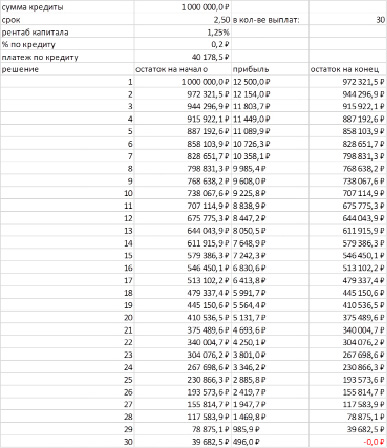
Источник: составлено автором.
Данный подход применим для анализа различных видов риска. Так, чтобы организовать бизнес, субъект хочет взять кредит в банке на сумму 1 000 000 на 2,5 года под 15% годовых, чтобы отдать его за 30 платежей. Тем не менее, в таком случае следует понимать, каким должен быть уровень рентабельности данных денежных средств, чтобы заемщик смог вовремя кредит и достичь необходимой прибыли в n-ный период (пусть в рамках задачи это будет последний период, а желаемая прибыль равняется расходам). В таком случае следует определить минимально удовлетворительный уровень показателя рентабельности капитала, функция чего может быть представлена в следующем виде:
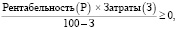
где анализируемыми величинами являются уровень рентабельности и являются.
Для решения данной задачи следует определить платеж по кредиту. Для этого применяется функция «ПЛТ», с помощью которой можно построить таблицу, строки которой будут отражать остаток на начало нового платежного срока; прибыль, определяемую через подбираемый параметр рентабельности; остаток на конец, за вычетом платежа по кредиту и прибыли.
В рамках описанной модели состояние выплаченного долга будет продемонстрировано в последней ячейке, соответствующей 30-ому, последнему платежу. Поскольку данные о рентабельности отсутствуют, значение данного показателя можно подобрать, используя одноименную функцию программы для достижения значения 0 в указанной ячейке. В результате описанных операций получается подбор параметров, отраженный в таблице 3.
Данный пример показывает, насколько цифровые инструменты могут быть эффективно использованы для комплексной оценки кредитного риска и риска банкротства. Благодаря применению данного подхода риск-менеджер может оперативно определить необходимый уровень отдачи денежных средств, что способствует выработке эффективного решения относительно использования долговых средств.
Описанные примеры из разных отраслей показывает, насколько разнообразны варианты использования специальных компьютерных программ, которые могут быть применены в рамках процесса управления практически любого риска. Впрочем, функции, используемые для таких базовых операций и предоставляющие базовые преимущества применения цифровых инструментов, представляют весьма ограниченный потенциал, особенно в сравнении с методами машинного обучения.
Собрание методов Machine Learning (ML) принципиально делится на два кластера: методы, основанные на дедуктивном анализе экспертов и использовании их наработок при формировании базы данных для дальнейшего использования, и те инструменты, который работают на основе прецедентного обучения – использовании эмпирических данных для поиска закономерностей и составления вероятного исхода [3].
В настоящее время существует проработанный инструментарий способов реализации процесса машинного обучения:
1. Обучение на основе модели «стимул-реакция». Такая модель создана по образу человеческого мозга, из-за чего за ней закрепилось альтернативное и более распространённое название – нейросеть. Использование нейросетей в компьютерных технологиях отражает попытку переноса функционала человеческого мозга на мощности вычислительных машин. Нейронные сети используются для решения сложных задач, которые требуют аналитических вычислений подобных тем, что делает человеческий мозг, но превосходящих их по объемам и уровню детализации. В данном контексте целесообразно назвать наиболее распространённые сценарии применения нейронных сетей:
a) классификация – распределение данных по параметрам. Такую работу может осуществить нейронная сеть, которая имеет доступ к соответствующей информации, например возрасте, платежеспособности, кредитной истории;
b) прогнозирование дальнейших событий. В таком случае перед алгоритмом ставится задачи определения дальнейшего поведения акций исходя из текущих условий фондового рынка, что представляет особый интерес для специалистов риск-менеджмента, которые могут использовать такой инструмент для прогнозирования рисков [5].
Прародителем современных нейросетей стал Adaboost: несмотря на хорошие результаты, работа алгоритма всегда была сопряжена со спекуляциями относительно природы вычислений. Дело в том, что обоснований работы алгоритма с его надстройками было мало, кто-то считал его прорывной технологией, тогда как другим подход казался малоприменимым и сопряженным жесткой переподгонкой (overfitting) [9].
2. Различные комбинации использования методов машинного обучения с «учителем» – субъектов, задающим необходимые условия. В зависимости от степени влияния человека исследователи выделяют следующие подходы к обучению алгоритмов ИИ:
– обучение без учителя;
Для каждого известного элемента выборки, с которой работает алгоритм, задается сценарий, объединяющий различные элементы в группы на основании специфичного правила. В данном подходе активно применяется теория кластеризации, объясняющая более корректную с точки зрения статистики группировку по определенным критериям посредством назначения весов элементов (например, по методу ближайших соседей) для понижения размерности данных или же использования информации о попарном сходстве объектов выборки между собой.
– обучение с частичным привлечением учителя;
Для части прецедентов задается под-алгоритм «ситуация и требуемое решение» (например, выделить в отдельный кластер все положительные значения, чтобы их просуммировать), а для иной части – исключительно «ситуация», в условиях которой, например, нужно без дополнительных манипуляций отсеять все отрицательные значения выборки.
– трансдуктивное обучение;
Речь идет об обучении с частичным привлечением учителя, при котором прогноз осуществляется только для прецедентов из тестовой выборки, не предполагая попытки его продления на основании замеченных закономерностей [6].
3. Бустинг – процесс, суть которого заключатся в построении нескольких взаимосвязанных рядов алгоритмов, в которых каждый следующий алгоритм стремится компенсировать недостатки композиции предыдущих. На практике данный метод применяется для уменьшения дисперсии полученных данных. В результате основу кода, спроектированного по модели бустинга, составляет обучение простых моделей с целью компиляции из них более точной, массивной единицы [2].
Схема метода и процесса обучения в таком случае не отличается особой сложностью: при добавлении следующего элемента, классификатора, присваивается определенный вес, оценка которого связана с итоговой точностью измерения. Определяемые веса пересчитываются (процесс называется пересчетом весовых коэффициентов) для внесения изменений в модель с целью уточнения результата: неверно классифицированные входные данные получают больший вес, а тогда как правильные данные вес теряют.
Наиболее широкораспространенным и универсальным вариантом бустинга в текущих реалиях принято считать градиентный бустинг. Логику метода следует рассмотреть через призму регрессионного анализа, на основе которого выстраивается какой-то алгоритм. Базовым предположением в линейной регрессионной модели является случайное распределение отклонений в области 0, сумма который приносит нулевой результат.
В свою очередь отклонения можно рассматривать в качестве ошибок, сделанных моделью. Хотя в моделях, основанных на деревьях решений, такого предположения не делается, если размышлять об этом предположении с позиции не статистики, но логики, можно заключить, что принцип распределения отклонений можно использовать для модели. Таким образом, принцип работы алгоритма заключается в итеративном применении этих паттернов отклонений и улучшении прогноза: как только учитель достиг момента, когда отклонения не имеют никакого паттерна, донастройка модели останавливается [4].
Искусственный интеллект получает все большее признание в различных отраслях благодаря потенциалу существенно изменить повседневную деятельность бизнеса (рисунок).
В сфере управления рисками AI/ML стал синонимом повышения эффективности и производительности при одновременном снижении затрат, что стало возможным благодаря способности технологий обрабатывать и анализировать большие объемы неструктурированных данных на более высоких скоростях при значительно меньшем вмешательстве человека. Технология также позволила банкам и финансовым учреждениям снизить операционные расходы, затраты на комплаенс и соблюдение нормативных требований, одновременно предоставляя финансовым институтам возможность принимать точные решения.

Классификация цифровых инструментов AI/ML Источник: составлено автором
Решения по управлению рисками на базе AI/ML также могут использоваться для управления модельными рисками (обратное тестирование и проверка моделей) и стресс-тестирования, как того требуют глобальные пруденциальные регуляторы, что обеспечивает для всех заинтересованных сторон следующие преимущества:
– повышенная точность прогнозирования;
Традиционные регрессионные модели зачастую неадекватно отражают нелинейные взаимосвязи между макроэкономикой и финансовыми показателями компании, особенно в случае стрессового сценария, тогда как машинное обучение обеспечивает повышенную точность прогнозирования благодаря способности моделей улавливать нелинейные эффекты между переменными сценария и факторами риска [10].
– оптимизированный процесс выбора переменных;
Процессы извлечения характеристик/переменных занимают значительное время в моделях риска, используемых для принятия внутренних решений. Алгоритмы ML, дополненные аналитическими платформами Big Data, могут обрабатывать огромные объемы данных и извлекать множество переменных. Богатый набор функций с широким охватом факторов риска способен привести к созданию надежных, основанных на данных моделей риска для стресс-тестирования [8].
– более комплексная сегментация данных;
Детализация и сегментация крайне важны для работы с меняющимся составом портфеля. В этой связи алгоритмы ML обеспечивают более качественную сегментацию и учитывают атрибуты сегментных данных, тогда как использование алгоритмов ML без контроля позволяет сочетать подходы к кластеризации на основе расстояний и плотности, что приводит к повышению точности моделирования и объяснительной способности.
В качестве практических кейсов использования ML/AI в риск-менеджменте банка можно рассмотреть способность цифровых инструментов к моделированию кредитного риска. Так, хотя банки традиционно используют модели кредитного риска для прогнозирования категориальных, непрерывных или бинарных переменных (дефолт/недефолт), поскольку ML-модели трудно интерпретировать и нелегко проверить для целей регулирования, последние активно внедряются в процессы оптимизации параметров и улучшения выбора переменных в существующих регуляторных моделях [7].
Заключение
В рамках настоящей работы автором проанализирован потенциал цифровых технологий для управления рисками деятельности частного банка. Автором приводятся примеры цифровых решений, которые могут быть применены в рамках процесса управления практически любым риском, а также рассматриваются сценарии применения технологий на основе искусственного интеллекта и машинного обучения, способных многократно повысить эффективность оценки рисков за счет более высокой точности прогнозирования и комплексной сегментации данных.
Определено, что методы построения деревьев решений на основе ИИ позволяют получить легко прослеживаемые и логичные правила принятия решений в условиях возникновения риска, несмотря на его нелинейность. В свою очередь методы обучения без контроля способны использоваться для изучения данных при традиционном моделировании кредитного риска, а методы классификации, такие как машины опорных векторов, позволяют прогнозировать ключевые характеристики кредитного риска, такие как PD или LGD для кредитов. Финансовые компании также все чаще нанимают внешних консультантов, которые используют методы глубокого обучения для разработки моделей прогнозирования доходов в стрессовых сценариях.
Библиографическая ссылка
Булатова Л.С. ПРИМЕНЕНИЕ ЦИФРОВЫХ ИНСТРУМЕНТОВ В ОБЛАСТИ РИСК-МЕНЕДЖМЕНТА // Вестник Алтайской академии экономики и права. 2024. № 8-1. С. 25-31;URL: https://vaael.ru/en/article/view?id=3617 (дата обращения: 01.08.2026).
DOI: https://doi.org/10.17513/vaael.3617